兒童食品市場蓬勃發(fā)展,各類打著“營養(yǎng)強(qiáng)化”“益智助長”旗號的產(chǎn)品層出不窮。這些看似專業(yè)的營銷概念背后,往往隱藏著高糖、高油的健康陷阱,正悄然培養(yǎng)著孩子們對不健康食品的依賴。
一、概念營銷的華麗外衣
市場上許多兒童食品通過精心設(shè)計的包裝和宣傳語,如“添加DHA促進(jìn)大腦發(fā)育”“富含鈣鐵鋅增強(qiáng)免疫力”等,讓家長產(chǎn)生“健康營養(yǎng)”的錯覺。實際上,這些產(chǎn)品可能同時含有過量的糖分和油脂。比如某些兒童酸奶,其含糖量甚至超過普通碳酸飲料;所謂的“兒童專用”餅干、膨化食品,脂肪和鈉含量也常常超標(biāo)。
二、高糖油依賴癥的形成機(jī)制
兒童天生偏愛甜味和油脂豐富的食物,食品企業(yè)正是利用這一特點,通過添加大量精制糖、氫化植物油等成分,制造出令人“上癮”的口感。長期食用這類食品,不僅會導(dǎo)致兒童味覺鈍化,對天然食物的接受度降低,還會形成對高糖油食物的心理依賴。更嚴(yán)重的是,這種飲食習(xí)慣容易引發(fā)肥胖、齲齒、糖尿病等健康問題,甚至影響孩子的學(xué)習(xí)能力和情緒穩(wěn)定性。
三、營銷策略與消費(fèi)誤區(qū)
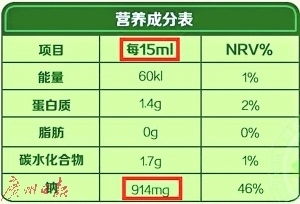
企業(yè)常采用明星代言、卡通形象授權(quán)等方式增強(qiáng)產(chǎn)品吸引力,同時在成分標(biāo)注上玩“文字游戲”——用“果葡糖漿”代替“白砂糖”,以“植物奶油”偽裝健康脂肪。許多家長因工作繁忙或缺乏營養(yǎng)知識,容易受廣告影響,誤將“兒童專用”等同于“健康安全”,忽視了查看配料表和營養(yǎng)成分表的重要性。
四、破解困局的應(yīng)對之策
家長應(yīng)提高食品鑒別能力,學(xué)會解讀營養(yǎng)標(biāo)簽,優(yōu)先選擇糖、鈉、脂肪含量較低的產(chǎn)品。培養(yǎng)孩子均衡飲食習(xí)慣,多提供新鮮蔬果、全谷物等天然食物,減少加工食品攝入。監(jiān)管部門也需加強(qiáng)兒童食品標(biāo)準(zhǔn)制定,明確糖、油、添加劑的限量要求,并對夸大宣傳的行為嚴(yán)格執(zhí)法。
面對琳瑯滿目的兒童食品,我們既要理性看待營銷概念,更要警惕高糖油依賴癥對下一代健康的潛在危害。只有家庭、企業(yè)、社會形成合力,才能為孩子們營造真正健康的飲食環(huán)境。